IPA-friendly transcripts, diarization with overlaps, and acoustic/event labels—with QA to your spec.
Capabilities
Each capability pairs illustrative imagery with how we deliver it at production quality.

Phonetic Transcription
IPA-style phones, stress, and dialect detail—not just words. Waveform-aligned (incl. multi-channel) for TTS, linguistics, and accent-robust ASR.
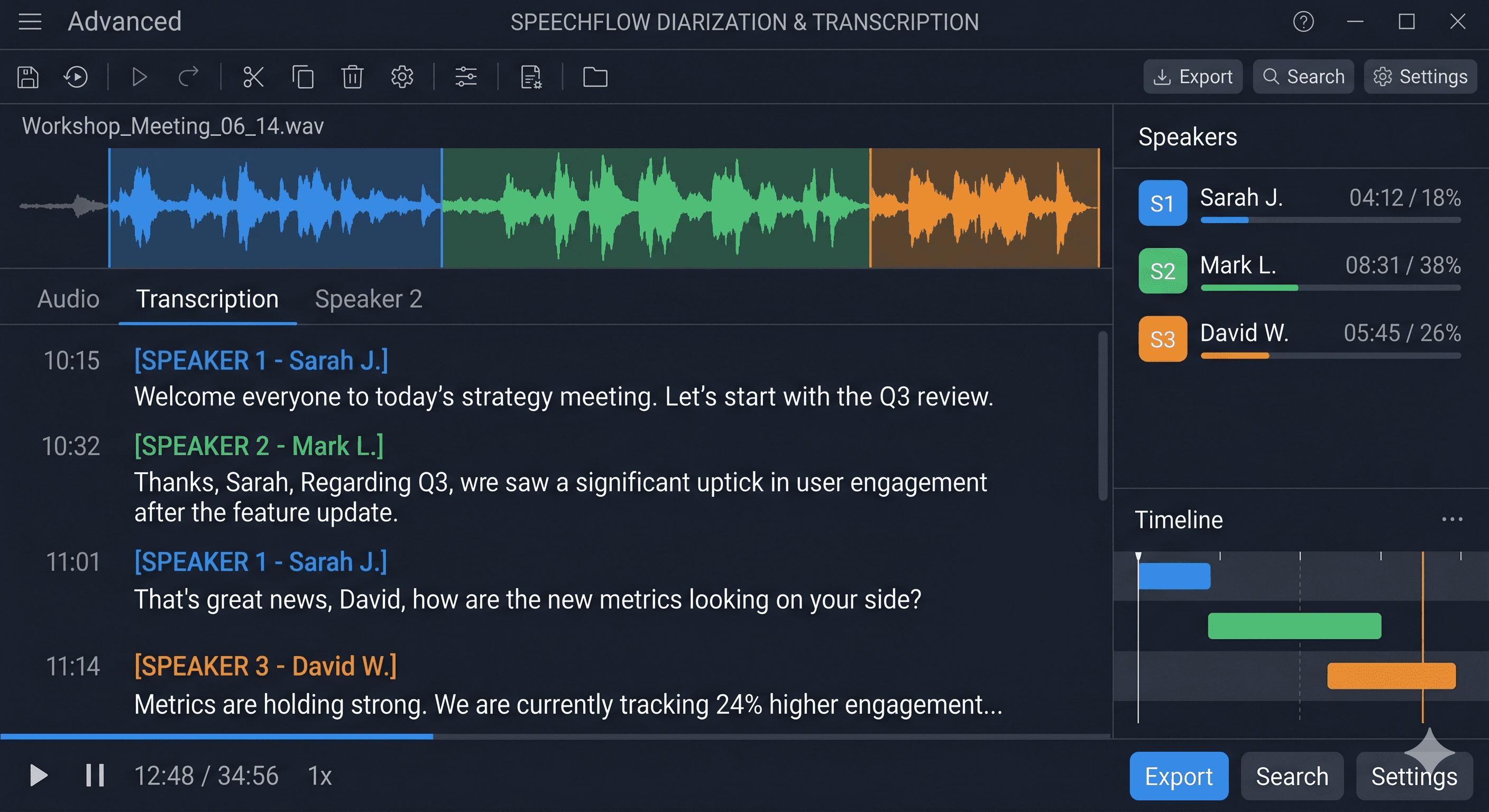
Speaker Diarization
Who spoke when—with overlaps and tight boundaries. Stable IDs across long calls and meetings; mono or multi-mic; millisecond-level segments for clean transcripts.

Audio Classification
Events, emotion, noise, and scene labels beyond speech. Discrete cues (alarms, glass break, …), stress/tone tags, ambient profiles for denoise, and clip-level context for security and automotive.