Pixel-accurate labels for detection, segmentation, and scene understanding—built for autonomy, retail, medical vision, and security at production scale.
Capabilities
Each capability pairs illustrative imagery with how we deliver it at production quality.

Bounding Boxes
Tight 2D/3D boxes for object detection and tracking. Multi-class boxes for pedestrians, vehicles, and obstacles with QA matched to your IOU rules—fast batches for autonomy, retail, and security.

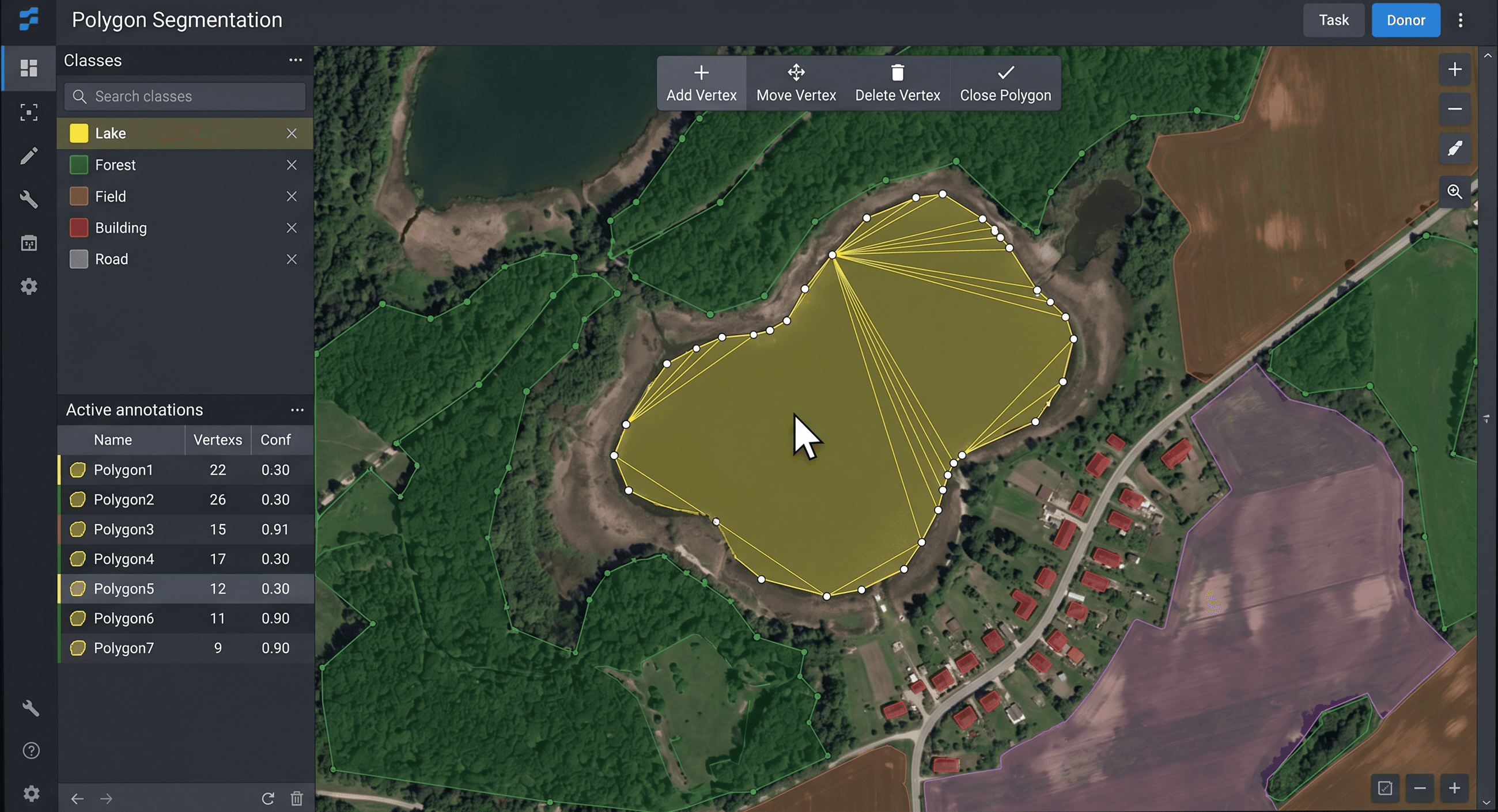
Polygon Segmentation
Vertex-accurate masks for irregular and organic shapes. Polygons beat boxes on curved objects—semantic or instance workflows for aerial, medical, and street scenes with tight edges and minimal bleed.

Polyline Annotation
Lanes, edges, wires, and markings as continuous polylines. Dense vertices for smooth curves; optional type, color, and direction tags for HD maps, ADAS, and path planning with clean intersections.

Keypoint Labeling
Pose, face, and custom skeletons for motion and HCI. Joints and landmarks with visibility/occlusion tags—sports, gestures, and clinical layouts aligned to your model topology.

Semantic Segmentation
Per-pixel class maps for full-scene context. Dense labels (road, sky, vegetation, people, …) with sharp boundaries—driving, medical, and geospatial QA at many classes per frame.